06 Mar Gestion des données manquantes
- Lorsqu’un paramètre n’a pas été mesuré pour tous les patients de l’étude, on parle de données manquantes
- Il existe peu d’études sans données manquantes
- En présence de données manquantes, il convient de les décrire et de choisir une stratégie pour les traiter
Les données manquantes sont un problème rencontré fréquemment dans les sciences de la vie, et les raisons de leur présence sont nombreuses (biais de mémoire, perdus de vue, données recueillies rétrospectivement à partir de dossiers médicaux, etc).
Il s’agit d’un problème, car ils peuvent être à l’origine de biais importants.
Certaines de ces données manquantes peuvent être le fruit du hasard (par exemple si un médecin remplit correctement 3 cahiers d’observation sur 4). Dans ce cas, l’échantillon reste représentatif de la population d’étude.
Les problèmes surviennent lorsque les données manquantes ne sont pas dues au hasard (par exemple si on soumet un questionnaire à des patients dépressifs pour mesurer leur niveau de dépression et que seuls les moins déprimés parviennent à le remplir correctement.)
Pour différencier les données manquantes dues au hasard de celles non dues au hasard, il est nécessaire de les décrire pour savoir si les patients ayant des données manquantes au hasard ont les mêmes caractéristiques que ceux n’ayant pas de données manquantes.
En présence de données manquantes, votre travail doit être d’abord de comprendre pourquoi ces données manquent et de le décrire dans votre article/thèse.
Plusieurs méthodes existent pour faire face à la présence de données manquantes et dépendent de nombreux facteurs.
Les techniques d’imputation
Pour contrebalancer la perte de puissance liée à la présence de données manquantes, les statisticiens ont recourt à des techniques d’imputation. Il est en effet dommage de se priver de l’information de tous les paramètres recueillis pour un patient s’il n’existe qu’un seul paramètre manquant. L’imputation consiste à attribuer une certaine valeur à la donnée manquante.
Une technique d’imputation souvent utilisée est l’imputation par la médiane. Il s’agit d’attribuer la valeur de la médiane du paramètre à tous les patients ayant des données manquantes.
D’autres techniques d’imputation sont utilisées, notamment l’imputation multiple par équation de chaîne, qui consiste à attribuer à la donnée manquante la valeur la plus probable en fonction des autres paramètres du patient, et à répéter cette opération plusieurs fois. Cette technique repose sur des modèles de régression et permet d’imputer les données de manière plus fiable en particulier lorsque les données manquantes ne sont pas dues au hasard.
Structure des données manquantes
Un graphique est particulièrement utile pour identifier rapidement les données manquantes. Son interprétation requiert un peu d’entraînement, mais au final, il est assez simple. Prenons l’exemple de graphique ci-dessous :
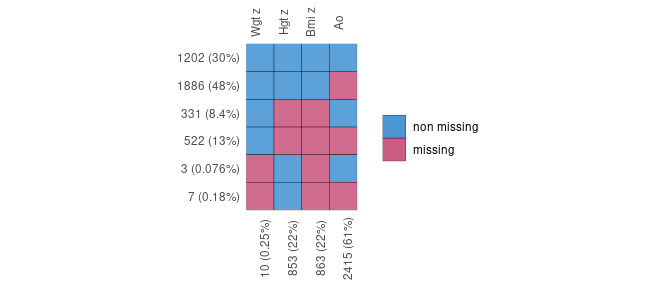
Ce graphique représente la structure des données manquantes. Les nombres en bas représentent le nombre (proportion) de valeurs manquantes pour chacune des variables ayant au moins une valeur manquante. Les lignes représentent les motifs de données manquantes. Ainsi, 10 valeurs de Wgt z, 853 de Hgt z, 863 de BMI z et 2415 de Ao sont manquantes. Sur l’ensemble de nos données :
- 30% des observations (patients) sont des complete cases : observations sans aucune donnée manquante,
- 48% ont toutes leurs valeurs renseignées à l’exception d’Ao.
- 8.4% ont à la fois Hgt z et Bmi z de manquant,
- 13% ont à la fois Hgt z, Bmi z et Ao manquants,
- 3 observations ont Wgt z et Bmi z manquants,
- 7 observations ont Wgt z, Bmi z et Ao manquants
Comment pvalue.io traite les données manquantes
pvalue.io filtre tout d’abord les paramètres (c’est-à-dire les colonnes de votre fichier) présentant plus de 20% de données manquantes : ces variables ne peuvent pas être introduites dans les modèles statistiques (dans l’exemple précédent, il s’agit de Hgt z, Bmi z et Ao). Il fait ensuite appel à un algorithme itératif : tant qu’il y a plus de 20% d’observations ayant au moins une donnée manquante, suppression de la variable ayant le plus grand nombre de valeurs manquantes.
- Lorsqu’un paramètre comporte des données manquantes, pvalue.io indique à l’utilisateur le nombre et la proportion de patients comportant au moins une donnée manquante. C’est cette proportion qui serait exclue de l’analyse en l’absence de traitement spécifique de ces données.
- Lorsque la proportion de patients présentant au moins une donnée manquante est inférieure à 5%, ces patients sont exclus du modèle.
- Lorsqu’un paramètre comporte moins de 20% de données manquantes, une imputation par équation de chaîne est réalisée.
Plus d’information sur l’algorithme de gestion des données manquantes.
LEGALLAIS
Posté à 19:25h, 15 avrilBonjour ! Comment puis-je nommer dans mon tableau Excel les données manquantes pour que le logiciel puisse le comprendre ?
Merci beaucoup pour votre site internet, c’est un véritable bijou !!
Kevin
Posté à 09:11h, 26 juilletBonjour, et merci pour ce message. Il faut juste que les cellules soient vides pour que pvalue.io les reconnaissent en tant que valeurs manquantes.