11 Jul Missing data handling
- When a parameter has not been measured for all patients in the study, we are talking about missing data
- There are few studies without missing data
- If missing data are present, they should be described and a strategy chosen to address them
Missing data is a common problem in the life sciences, and there are many reasons for their presence (memory bias, loss to follow-up, data collected retrospectively from medical records, etc.).
This is a challenge, because in addition to the fact that their presence reduces the power of the study (by reducing the sample size of the study — statistical models only use patients with all the parameters of interest filled in —), they can cause significant biases.
Some of these missing data may be due to chance (for example, if a physician correctly fills out 3 out of 4 case report forms). In this case, the sample remains representative of the study population.
Problems arise when missing data are not random (for example, if a questionnaire is submitted to depressed patients to measure their depression level and only the least depressed are able to complete it correctly).
To differentiate between random and non-random missing data, it is necessary to describe the data to determine whether patients with missing data have the same characteristics as those without missing data.
Several methods exist to deal with the presence of missing data and depend on many factors.
Imputation methods
To compensate for the loss of power due to missing data, statisticians use imputation techniques. It is indeed a pity to omit the information of all the data collected for a patient if there is only one missing parameter. Imputation is the process of assigning a certain value to the missing data.
A frequently used imputation technique is imputation by the median. The median value of the parameter is assigned to all patients with this parameter missing.
Other imputation techniques are used, including multiple imputation by chain equation, which consists of assigning the most probable value to the missing data based on the patient’s other parameters and repeating this operation several times. This technique is based on regression models and allows data to be imputed more reliably, especially when the missing data are not due to chance.
Missing Data Patterns
A figure is particularly useful for quickly identifying missing data. Interpreting it takes some practice, but in the end it is quite simple. Let’s take the example figure below:
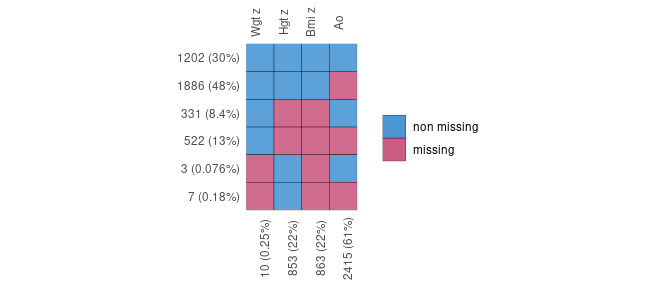
This figure represents the structure of the missing data. The numbers at the bottom represent the number (proportion) of missing values for each variable with at least one missing value. The rows represent the missing data patterns. In this example, 10 values of Wgt z, 853 of Hgt z, 863 of BMI z and 2415 of Ao are missing. Out of all our data:
- 30% of the observations (patients) are complete cases: observations without any missing data,
- 48% have all their values filled in except for Ao,
- 8.4% have both Hgt z and Bmi z missing,
- 13% have simultaneously Hgt z, Bmi z and Ao missing,
- 3 observations have both Wgt z and Bmi z missing,
- 7 observations have Wgt z, Bmi z and Ao missing
How pvalue.io handles missing data
pvalue.io first filters parameters (i.e. the columns of your file) with more than 20% missing data: these variables cannot be input into the statistical models (in the previous example, these are Hgt z, Bmi z and Ao). It then uses an iterative algorithm: as long as there are more than 20% of observations with at least one missing value, delete the variable with the highest number of missing values.
- When a parameter has missing data, pvalue.io indicates to the user the number and proportion of patients with at least one missing data. This is the proportion that would be excluded from the analysis in the absence of specific processing of these data.
- When the proportion of patients with at least one missing data is less than 5%, these patients are excluded from the model.
- When a parameter has less than 20% missing data, a chain equation imputation is performed.
No Comments